
こんにちは!うっちーです!
この記事を書くために、ブログを生やしてしまいました…。
そんな話はさておき。
一昨日開催された ABC372 にて、「Buildings」というD問題 が出題されました。
この問題のdiffは、901(緑下位) だったのですが、僕の解法からするにそんなわけないので
緑コーダーの僕がコンテスト中に通したトンデモ解法を記しておきたいと思います。
これを通してる全人類マジで頭良すぎ。
今回のACコード:https://atcoder.jp/contests/abc372/submissions/58037319
問題概要
https://atcoder.jp/contests/abc372/tasks/abc372_d
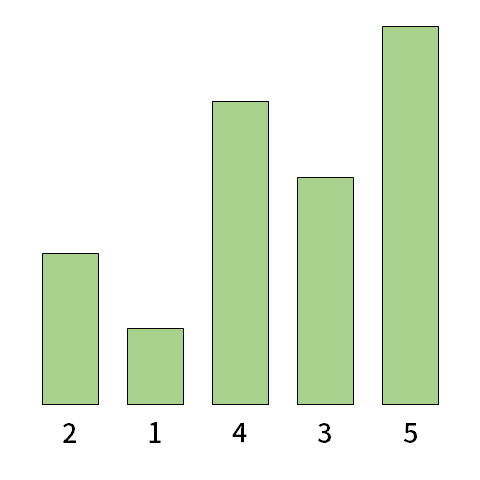
ビル\(1\), ビル\(2\), …, ビル\(N\)の\(N\)棟のビルがこの順で一列に並んでいます。
ビル\(i\) \((1 \leq i \leq N)\) の高さは\(H_{i}\)です。各\(i=1, 2, …, N\)について、次を満たす整数\(j\) \((i \lt j \leq N)\) の個数を求めてください。
- ビル\(i\)とビル\(j\)の間にビル\(j\)より高いビルが存在しない。
考察
では、ここから考察をしていきます。
(オーダー計算などが間違っている場合があります。何かお気づきの方はご連絡ください。)
まずこの問題を愚直に解こうとすると、次のようになります。
- 2重for文で\(i\)と\(j\)を動かす → \(O(N^{2})\)
- 各\((i, j)\)について、条件を満たすかどうか調べる → \(O(N)\)
よって、元の問題を解くのに\(O(N^{3})\)かかるので、当然無理です。
そこで、効率的な方法を考える必要があります。
この問題を解くうえで、特にいやらしいところを考えます。
それはズバリ、「各\(i\) について条件を満たす整数\(j\)の個数を求めなければならないのに、その条件が \(H_{i}\)ではなく、\(H_{j}\)によって決まる」というところです。
これが原因で、各\(i\) について、「答えをまとめて求める」ことができません。
そこで、元の問題を次のように言い換えることにします。
問題A
ビル\(1\), ビル\(2\), …, ビル\(N\)の\(N\)棟のビルがこの順で一列に並んでいます。
ビル\(i\) \((1 \leq i \leq N)\) の高さは\(H_{i}\)です。各\(j=1, 2, …, N\)について、次を満たす整数\(i\) \((1\leq i \lt j \leq N)\) の個数を求めてください。
- ビル\(i\)とビル\(j\)の間にビル\(j\)より高いビルが存在しない。
このように言い換えることによって、最初に紹介した愚直解(下に再掲)の2つ目の部分を高速化できるようになります。
- 2重for文で\(i\)と\(j\)を動かす
- 各\((i, j)\)について、条件を満たすかどうか調べる
この2つ目の部分に着目して、一般化した問題文を書いてみると、次のようになります。
問題B
長さ\(N’\)の配列\(H’\)があります。
次のようなクエリが\(Q\) 個与えられるので処理してください。
- \(L\)と\(R\) が与えられます。 \((1 \leq L \lt R \leq N)\)
- \(L \lt i \lt R \) を満たす\(H’_{i}\)の最大値を求めたとき、それが\(H’_{R}\) より大きければ Yes、そうでなければNoと出力してください。
では、この問題Bを高速に解くにはどうすればいいでしょうか?
答えは簡単です。区間の最大値を求めるセグメントツリーを使えばいいのです。
(今回は値の更新がないため、左右から累積maxをとっても同じことができます。)
セグメントツリーでは、その要素数を\(N\)とすると、次の操作を\(O( \log N )\)で行うことができます。
- \(i\)番目の要素に\(X\)を代入
- \(L\)番目の要素から\(R\)番目の要素の最大値を求める
問題Bを解くには、値の代入\(N\)回と最大値を求めるクエリが\(Q\)回実行されるので、
\(O((N+Q) \log N )\)でこの問題Bを解くことができるようになりました。
元の問題Aに戻ると、問題Bの各変数の値は次のようになります。
\(N’=N\)
\(Q=N^{2}\) ※厳密には違います。
つまり、問題Aを \(O((N+N^{2}) \log N )\) すなわち \(O(N^{2} \log N )\) で解くことができるようになりました。
とはいえ、まだオーダーに\(N^{2}\)が含まれているので、もちろんTLEです。
この\(N^{2}\) は、何の計算を表しているかというと、愚直解(下に再掲)の1つ目の部分です。
- 2重for文で\(i\)と\(j\)を動かす
- 各\((i, j)\)について、条件を満たすかどうか調べる
つまり、この部分を何とかすればTLEを回避することができるということです。
そこで、問題Aをもう一度思い出してみます。
問題A (再掲)
ビル\(1\), ビル\(2\), …, ビル\(N\)の\(N\)棟のビルがこの順で一列に並んでいます。
ビル\(i\) \((1 \leq i \leq N)\) の高さは\(H_{i}\)です。各\(j=1, 2, …, N\)について、次を満たす整数\(i\) \((1\leq i \lt j \leq N)\) の個数を求めてください。
- ビル\(i\)とビル\(j\)の間にビル\(j\)より高いビルが存在しない。
問題Aは、各\(i\)について考えていた元の問題を各\(j\)について考える問題に言い換えましたね。
そこで、各\(j\)についての問題を高速に解くことを考えます。
この問題Aをさらに少し言い換えてみます。
問題Aは、「各\(j\)について、条件にあてはまる\(i\)の数を求める」と言い換えることができます。
また、「各\(j\)について、条件にあてはまる\(i\)の区間を求める」ことができれば問題Aに解答することができます。
ここで、重要な事実があります。
それは、「各\(j\)について、条件にあてはまる\(i\)の区間と条件にあてはまらない\(i\)の区間の境界はただ1つしかない」ということです。
つまり、「各\(j\)について、条件にあてはまる\(i\)の区間と条件にあてはまらない区間の境界部分」を求めれば十分であることがわかります。
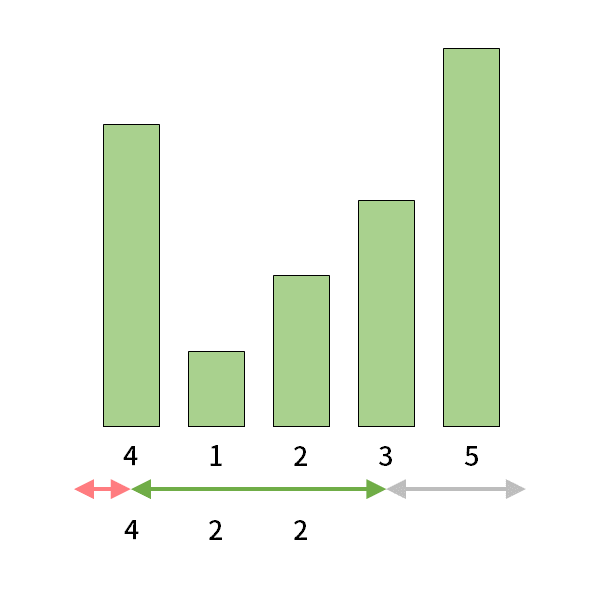
上図は、\(j=3\) の場合です。
灰色の矢印部分の\(i\)は \((1\leq i \lt j \leq N)\)を満たさないので、考えません。
緑色と赤色の矢印部分が\((1\leq i \lt j \leq N)\)を満たす\(i\)の範囲です。
上図の下部に書かれている数字は、「\(j\)を決めたとき、各\(i\) \((1\leq i \lt j \leq N)\)から\(j\)までの区間の最大値」を表しています。
この図を右から左に見ていくと、この値が初めて\(H_{j}\)を超える境界部分は明らかに1つしかありません。
(上図における、緑色と赤色の矢印の境界部分です。)
「\(j\)を決めたとき、各\(i\) \((1\leq i \lt j \leq N)\)から\(j\)までの区間の最大値」を求めていくので、当然、右から左に見ていくと、単調増加になります。
よって、このただ1つの境界を求めたいと思います。
このようにデータが単調増加(または減少)で、ある区間とある区間のただ1つの境界部分を高速に求めたいときは、二分探索を使うことができます。
なお、今回は配列ではなく、セグメントツリーでの区間最大値を求めるクエリの結果をもとに二分探索を行います。
これを「答えを二分探索」をするといいます。
(ここで求めるものは、元の問題の「答え」ではありませんが、このような場合でも一般的に「答えを二分探索」と呼ばれている気がするので、ここではそう呼ぶことにします。)
\(N\)回の二分探索には、\(O( \log N )\) かかりますが、今回は二分探索の各ステップごとに、セグメントツリーで区間最大値を求める操作 \(O( \log N ) \) がかかります。
また、セグメントツリーに各値を代入するのに、\( O( \log N) \)かかります。
よって、問題A 全体を\(O( N \log N + N \log N \cdot \log N )\) すなわち \(O( N \log N +N \log^{2} N )\) で解くことができました。
これで問題Aを高速に解くことができるようになりました。
…が、まだ対応しなければいけない問題があります。
それは、問題Aで求めた情報の形式が元の問題で要求されていた出力形式と異なるということです。
そこで、問題Aで求めた情報を元の問題の形式に変換することを考えます。
問題Aで要求されていたのは、「各\(j\)について、条件を満たす\(i\)の数」でしたが、先ほどの考察で「各\(j\)について、条件にあてはまる\(i\)の区間を求める」ことにしてきたのでした。
そこで、この情報をもとに元の問題の形式に変換することを考えます。
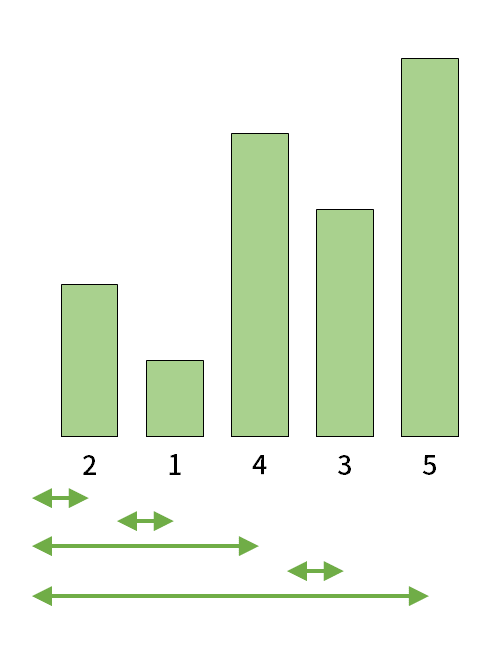
「各\(j\)について、条件にあてはまる\(i\)の区間」が既に求まっているということは、上図のような情報が既に求まっているということになります。
そして、各要素の下にある矢印の本数が変換後に求められるべき値です。
この変換について、一般化した問題文を書いてみると、次のようになります。
(ここで、\(Ans’_{i}\)を各\(i\)についての答えを格納する配列とします。)
問題C
長さ\(N’\)の配列\(Ans’\)があります。
次のようなクエリが\(Q\) 個与えられるので処理してください。
- \(L\)と\(R\) が与えられます。 \((1 \leq L \leq R \leq N)\)
- \(L \leq i \leq R \) を満たす\(Ans’_{i}\)の値を+1する。
これらのクエリをすべて処理した後の\(Ans’_{i}\) \((1 \leq i \leq N’)\) を出力してください。
この問題Cを解くことを考えます。
問題Aを解く過程で求められた区間は、全部で\(N\)個です。
つまり、問題Cの\(Q\)を問題Aの\(N\)を使って表すと次のようになります。
\(Q=N\)
ここで、この\(N\)個の各区間内の要素数の最大値をおおざっぱに\(N\)個と見積もったとき、
これらのクエリを愚直に処理すると、\(O(N^{2})\)かかってしまいます。
これでは、ここまでの努力も水の泡…明らかにTLEしてしまいます。
もうここまで読み進めてきたつよつよな皆さんならお分かりかと思いますが、このような区間加算のクエリを高速に処理するときは、いもす法が使えます。
いもす法を使うと、各クエリの処理に \(O(1)\)かかるので、\(N\)個のクエリを処理するのに \(O(N)\)かかります。
また、 出力時の加算処理に \(O(N)\) かかります。
よって、\(O(N + N)\) すなわち \(O(N)\) で問題Cを解くことができるようになりました。
ここまでの処理すべてを組み合わせたアルゴリズムのオーダーを考えてみると、 \(O(N \log N + N \log^{2} N + N)\) となります。
問題A, 問題B, 問題Cを高速に解けるようになったので、元の問題を十分高速に解くことができるようになりました。
まとめ
今回は、様々なアルゴリズムやテクニックを駆使する「トンデモ解法」をご紹介しました。
最後に、今回登場したアルゴリズムやテクニックをまとめておきます。
- 問題の言いかえ、主客転倒
- セグメントツリー
- 答えを二分探索
- いもす法
ちなみに、コンテスト中はこれらに加えて、「後ろから見る」ということもしました。
これは、問題を解くうえで必要ないことではあるのですが、答えを二分探索など諸々の実装をしていく中で、
「配列\(H\)そのものをreverseした方が実装をバグらせにくそう」と思ったからです。
ぜひ皆さんもこの問題をこのトンデモ解法でACしてみてくださいね!
(同じ解法だった人をあまり見つけられていないので、居たらぜひ教えてください。)
今回のACコード:https://atcoder.jp/contests/abc372/submissions/58037319
余談
コンテスト中、問題文の「ビル\(i\)とビル\(j\)の間」という表現を曖昧に理解してしまい、実装をバグらせて大幅にタイムロスしてしまいました…。
形式的に書いておいてくれたらよかったなぁ…と。
